来源:
[0002.哔哩哔哩-【个人向】CTF pwn 入门-P2高清版]_哔哩哔哩_bilibili
PPT链接
PWN.pptx - Microsoft PowerPoint Online
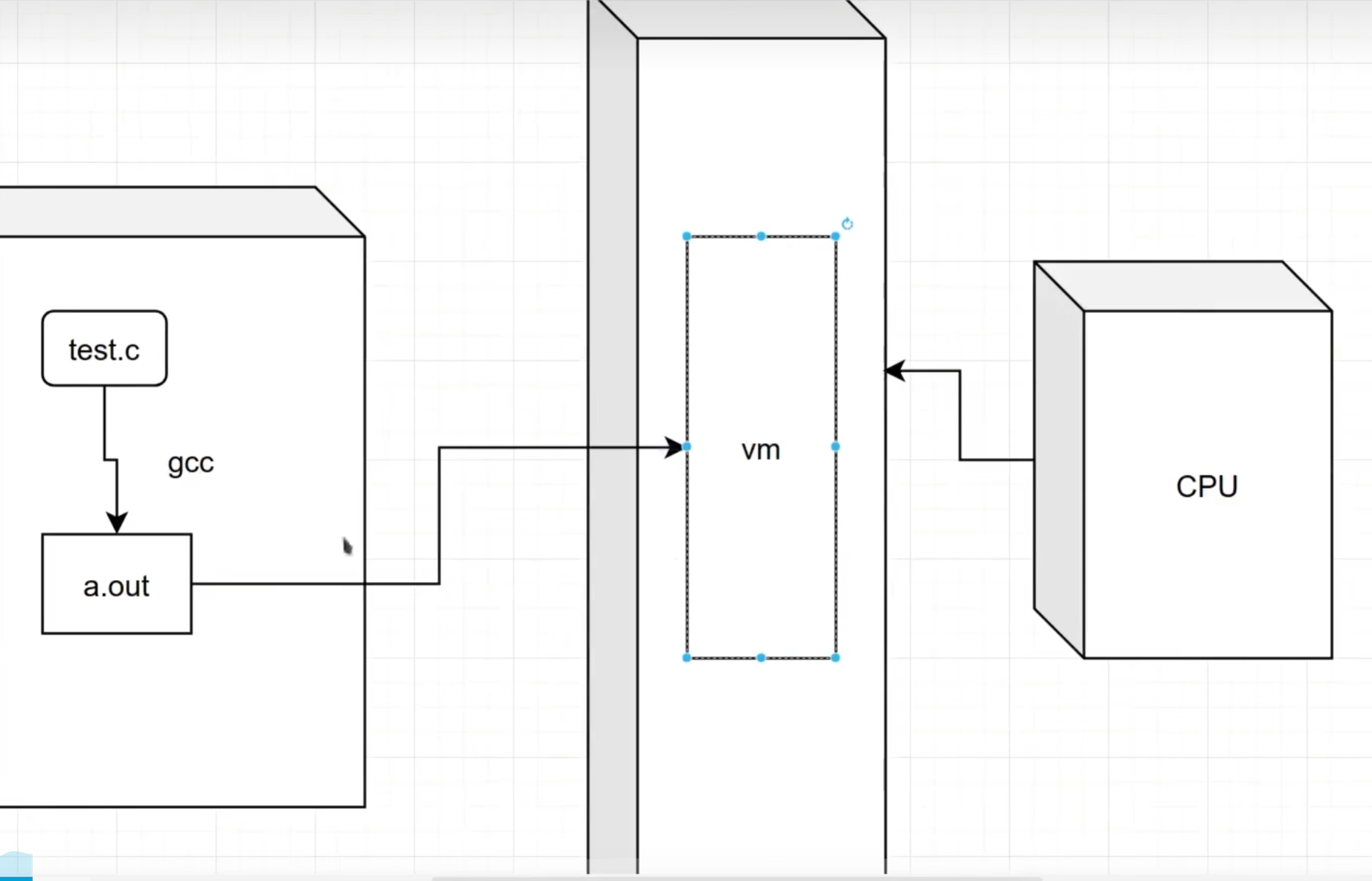
第一节:可执行文件、ELF文件结构
探讨从test.c到a.out的过程。研究一下a.out的结构
第二节:程序装载和运行内存
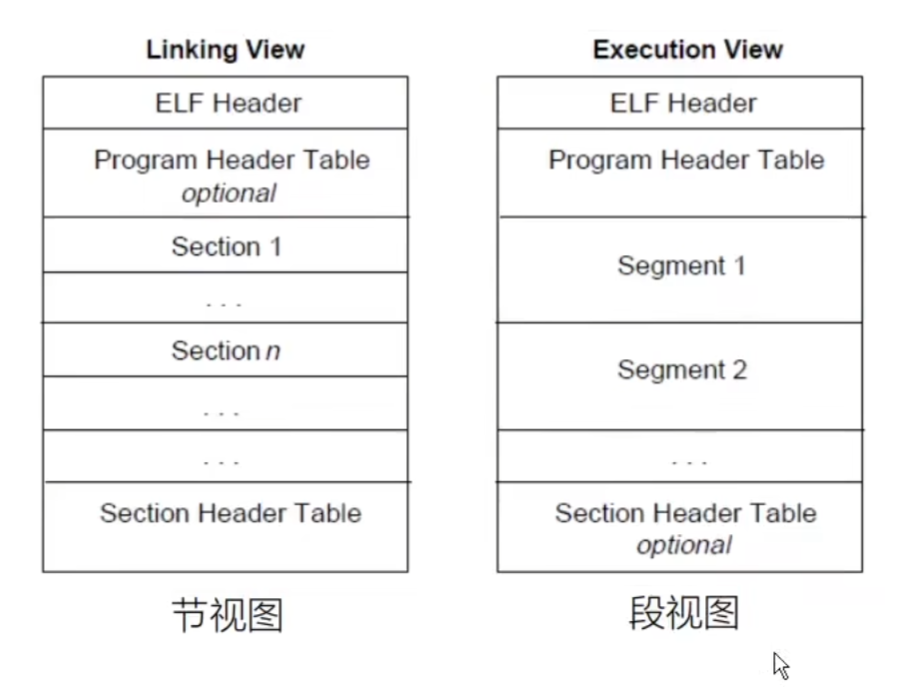
节视图是放在磁盘中划分功能的,段视图是程序装载到内存中来划分不同读写权限的。
看图说话:
[IMPORTANT]
权限相同的节归在一起成了段。
这个合并的过程是由 Linker 来完成的
从ELF文件到虚拟内存空间这个映射过程是由操作系统(OS)来完成的 (所以上图仅供Linux参考)
图中发现,.rodata这个数据节被划分到了Code段中。这是为什么? ——只依据权限划分
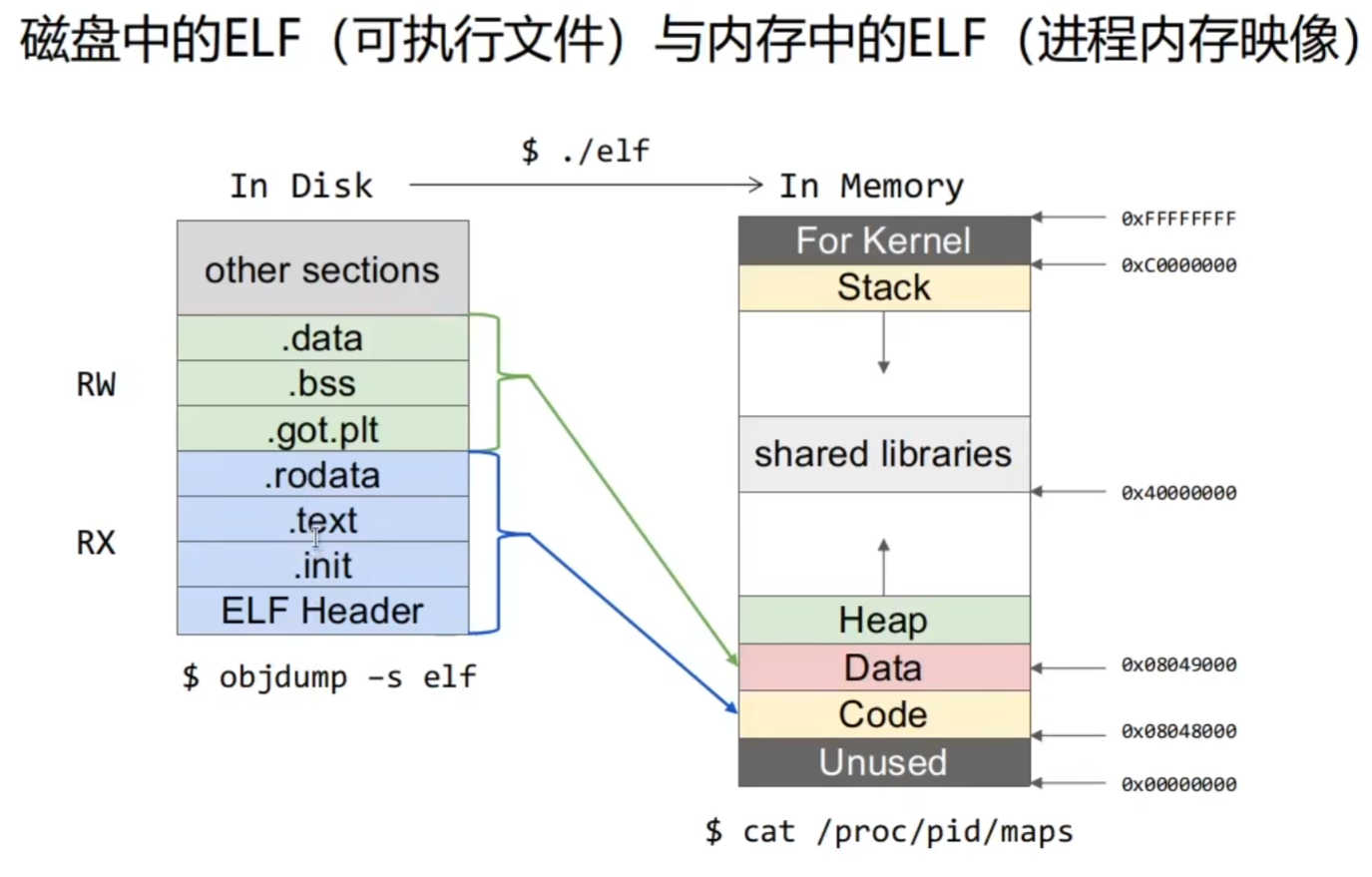
可执行程序内容只占了一部分内存区域。左边的ELF文件,实际上只有右边的Data和Code两个小长方形。其他是什么后面再说
地址以字节编码,常以十六进制表示。
虚拟内存用户空间每个进程一份
虚拟内存内核空间所有进程共享一份
虚拟内存mmap段中的动态链接库仅在物理内存中装载一份
虚拟地址空间(虚拟内存)和物理内存
x86-LInux(32位的进程虚拟地址空间) 一共4GB(整个4GB对应内存中的ELF)
用户空间分3GB,1GB共享内核空间。(节省资源的目的)
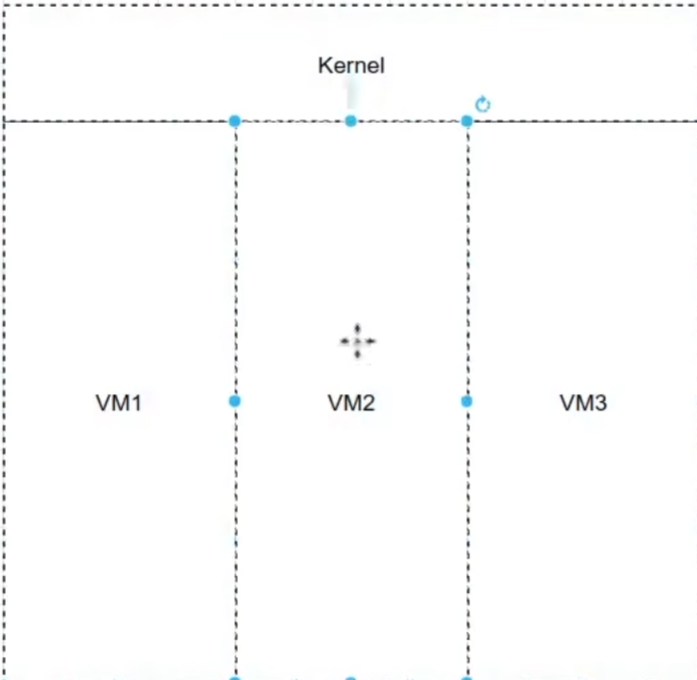
如果是64位进程虚拟地址空间,地址的有效位其实是6个字节。因为这足够大了
段与节

text节就是我们的主程序
一个段是节的高层次。
段视图用于进程的内存区域的rwx权限划分
节视图用于ELF文件编译链接时与磁盘上存储的文件结构的组织
举个例子
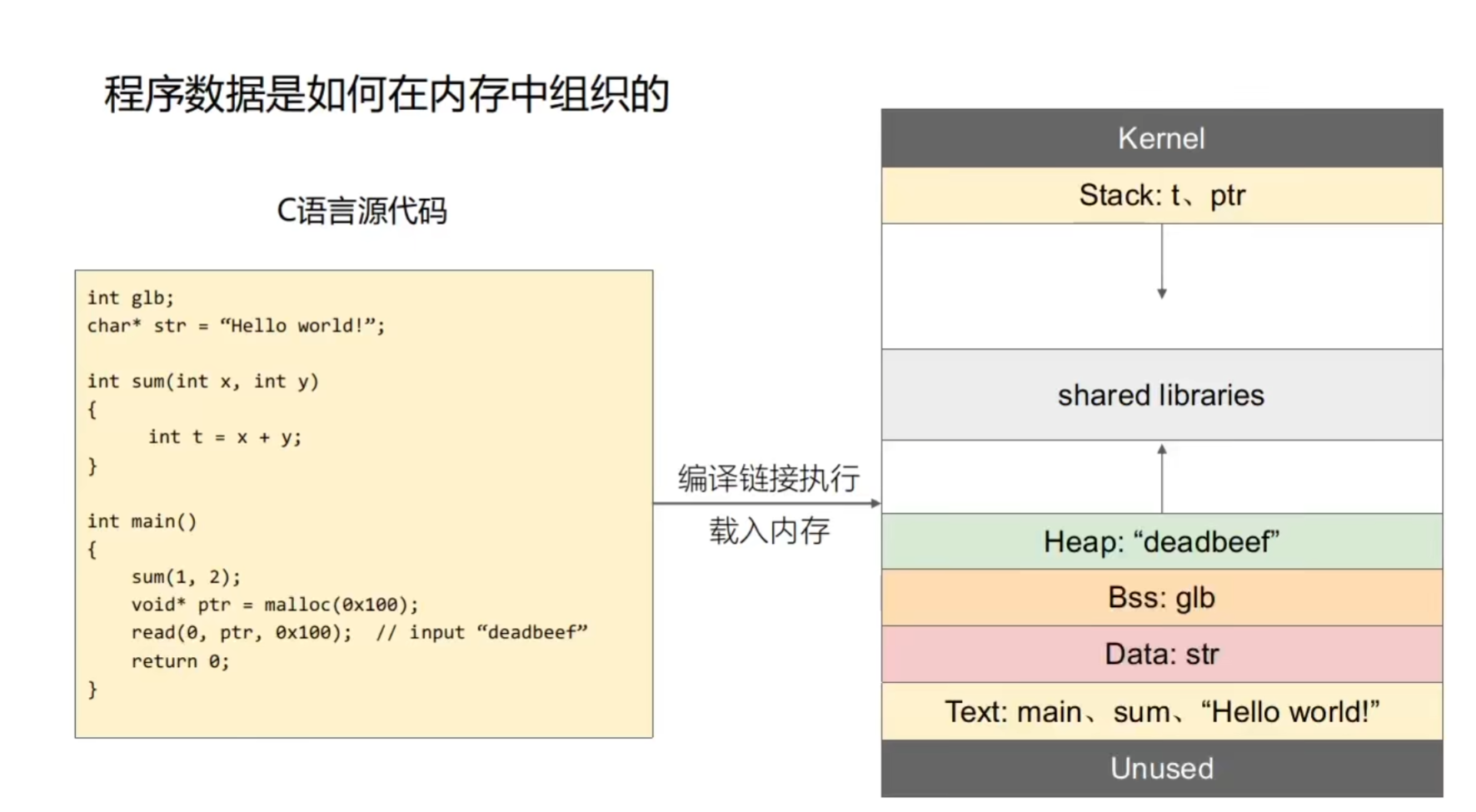
glb作为没有赋初值的全局变量,不占磁盘空间但占由内存空间。储存在Bss中
“Hello World”虽然是一个字符串 常量,但是在Text段中(一般认为这是代码成分)。这是因为它只有可读性,属于Text段中的.rodata节
函数被编译后还是数据,数据是被用来执行的代码。既然是代码段,所以在Text段。
函数调用在栈中
局部变量ptr在栈中
malloc申请的空间在堆中
x,y在哪儿与系统架构有关。AMD64在寄存器,x86在栈
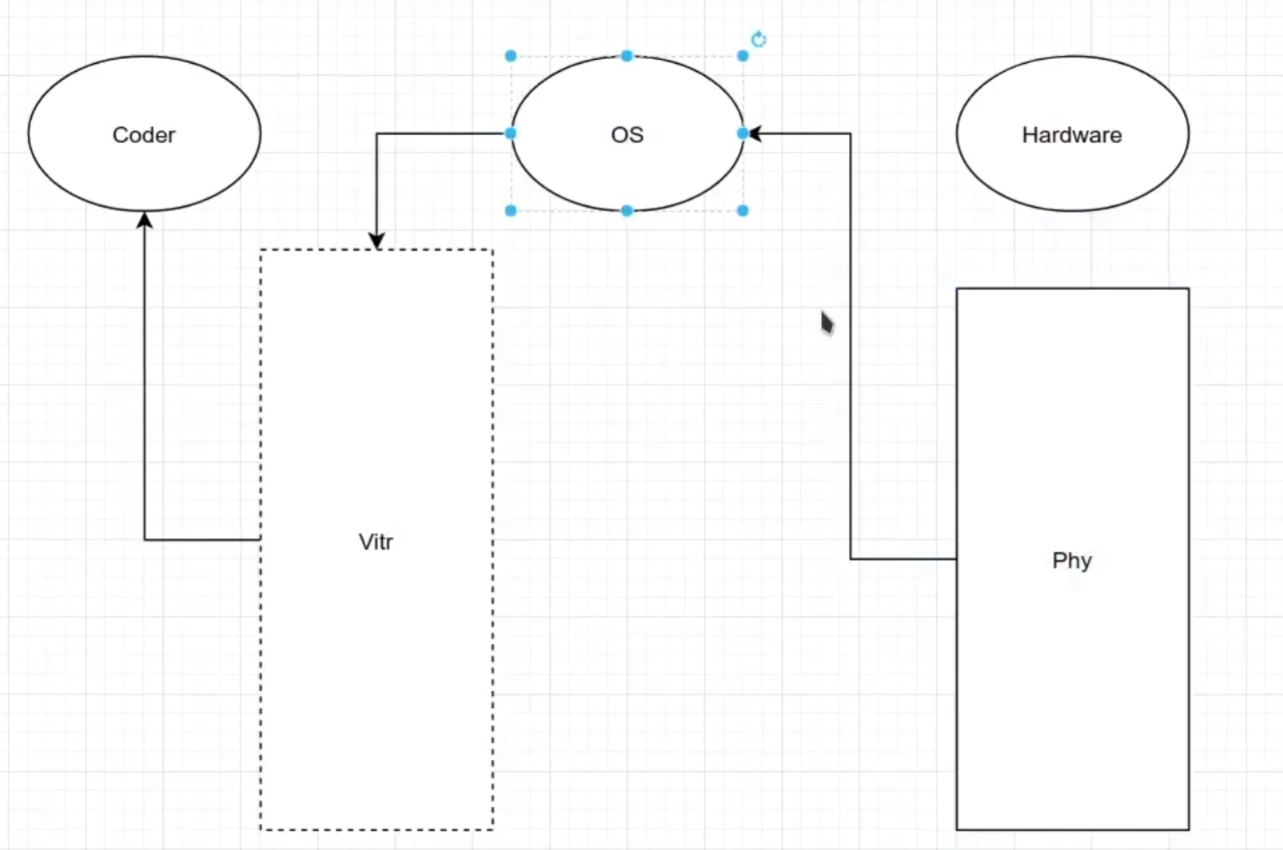
第三节:CPU与进程的执行
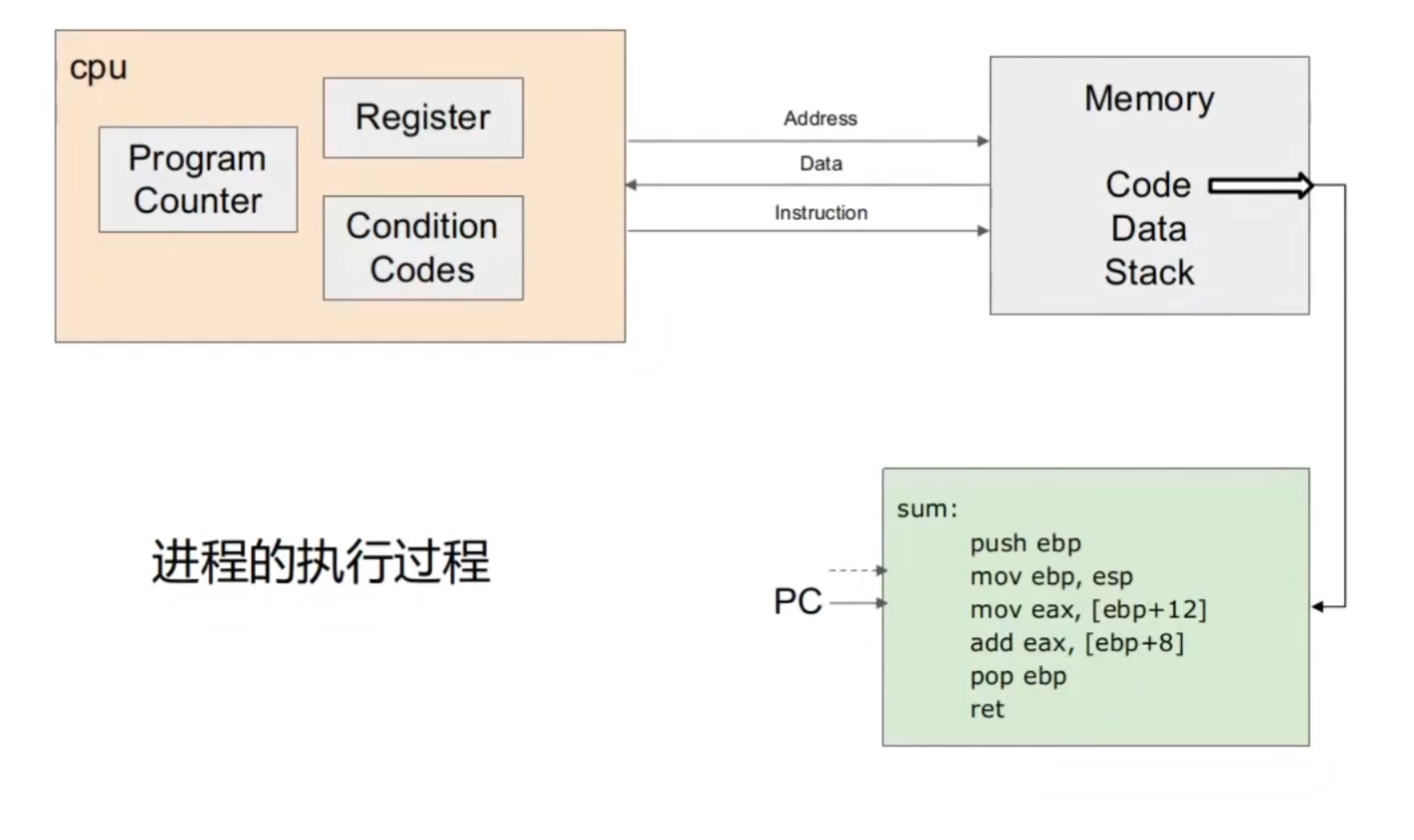
CPU通过总线向内存发送访存指令。
第四节:装载与汇编
汇编这个,课堂任务,懒得写
装载这个,没学会,写不出来
第五节:栈溢出基础
函数调用栈
研究的是x86嗷
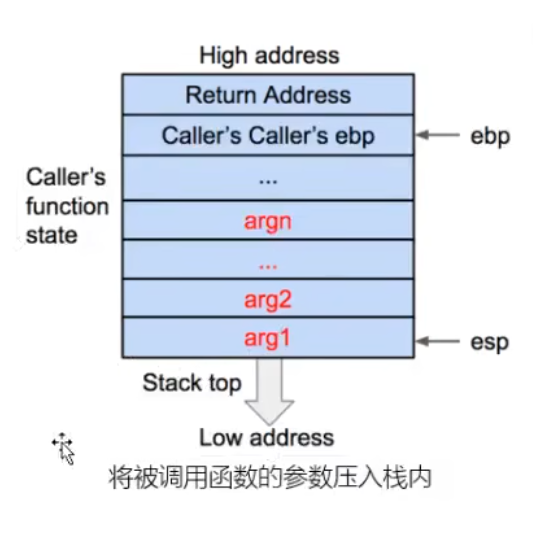
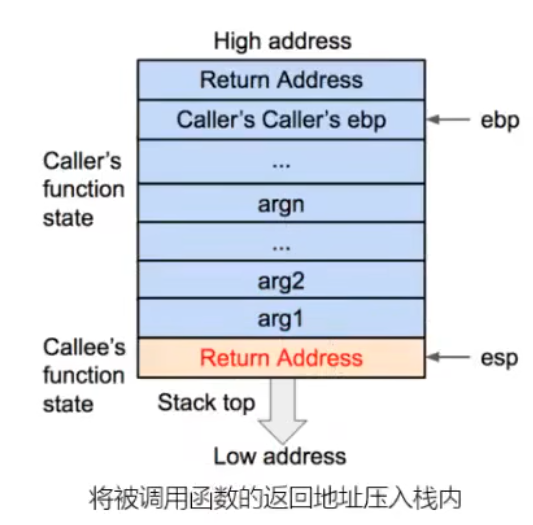
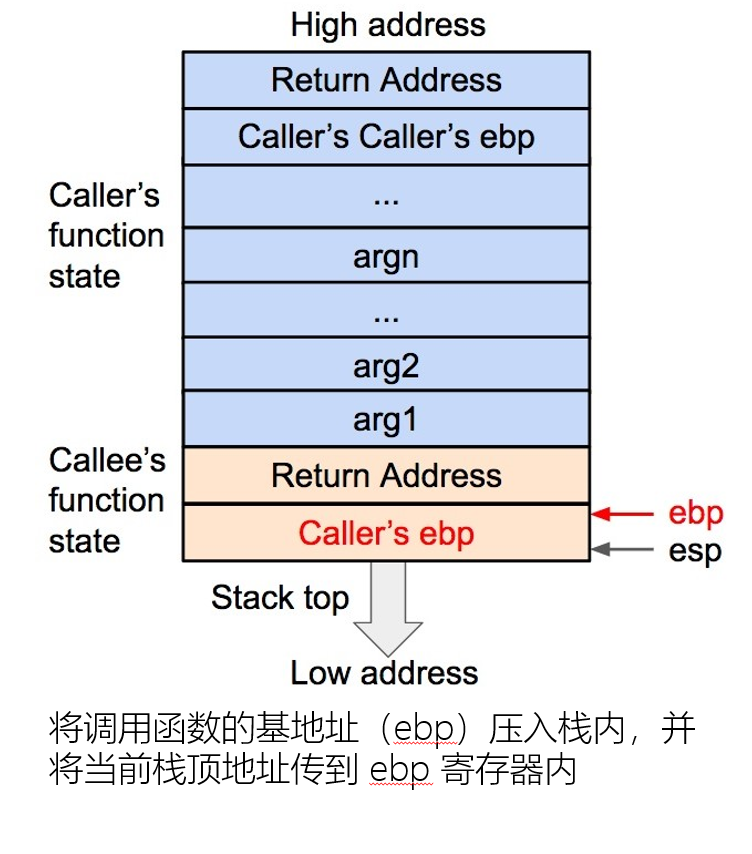
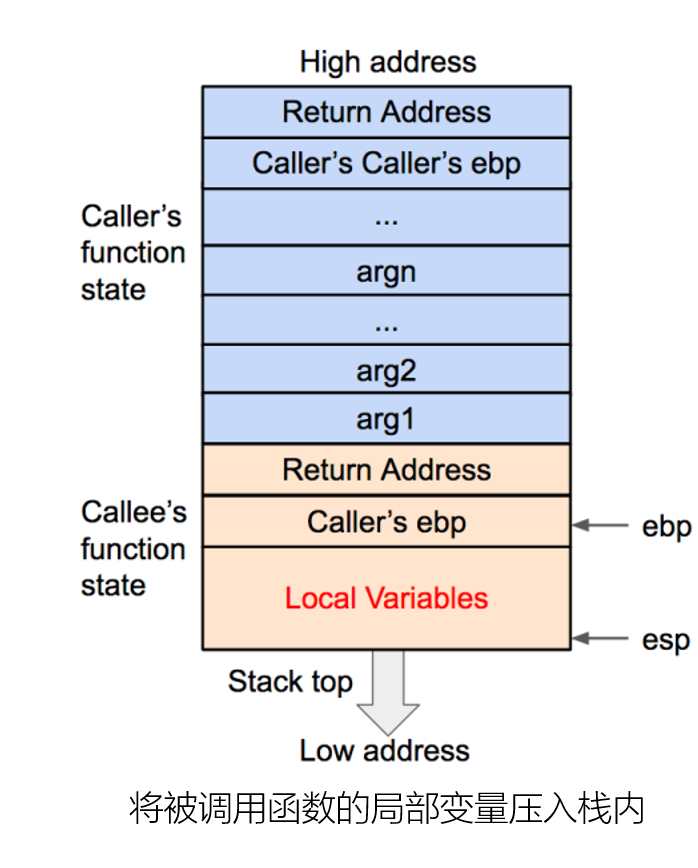
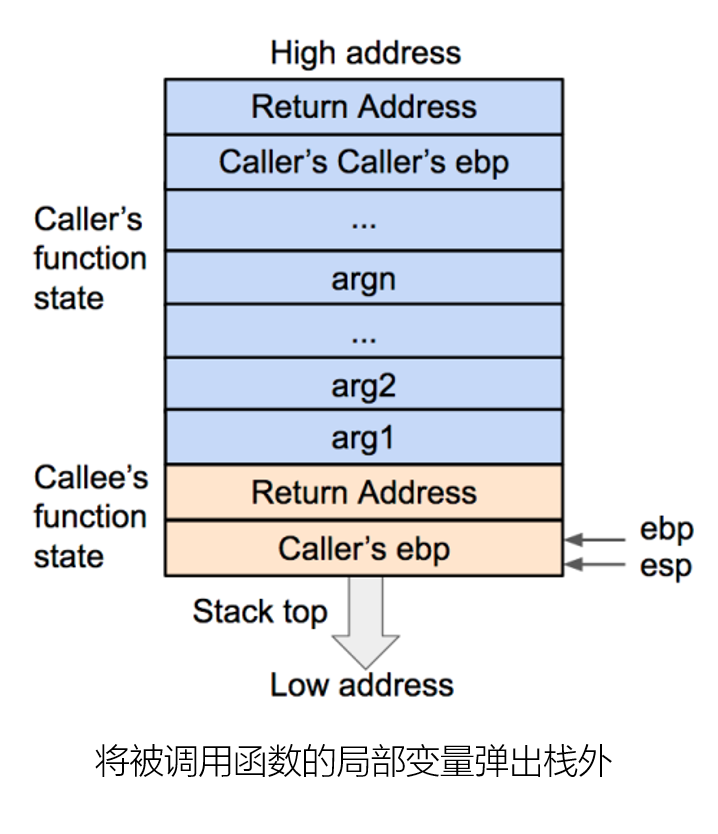
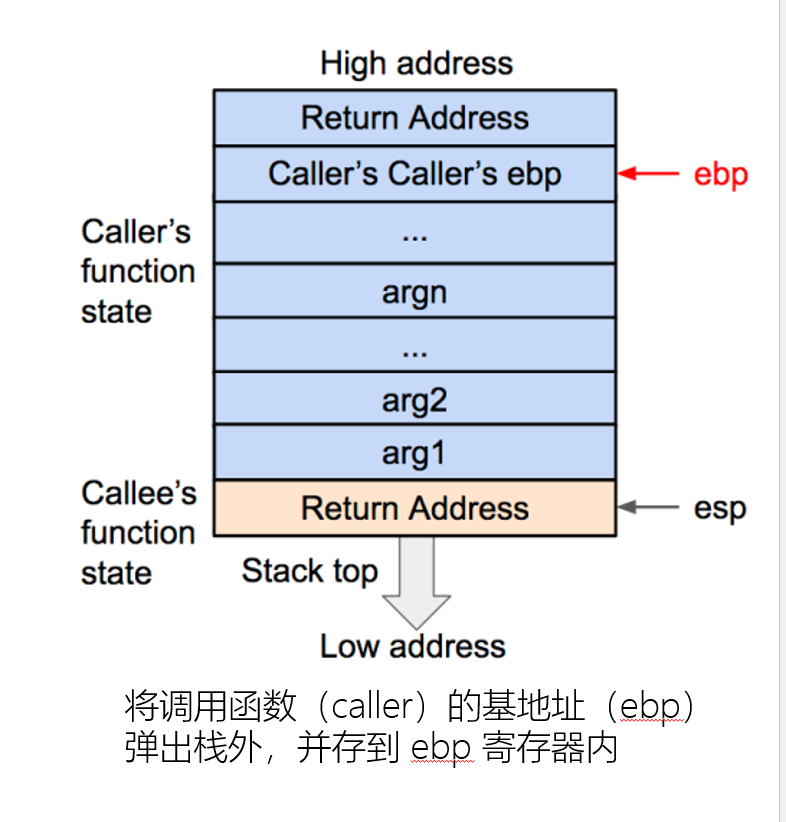
函数状态主要涉及三个寄存器——esp、ebp、eip。
esp用来存储函数调用栈的栈顶地址,在压栈和退栈的时候发生变化。
ebp用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。
eip用来存储即将执行的程序指令的地址,cpu依照eip的存储内容读取指令并执行,eip随之指向相邻的下一条指令。
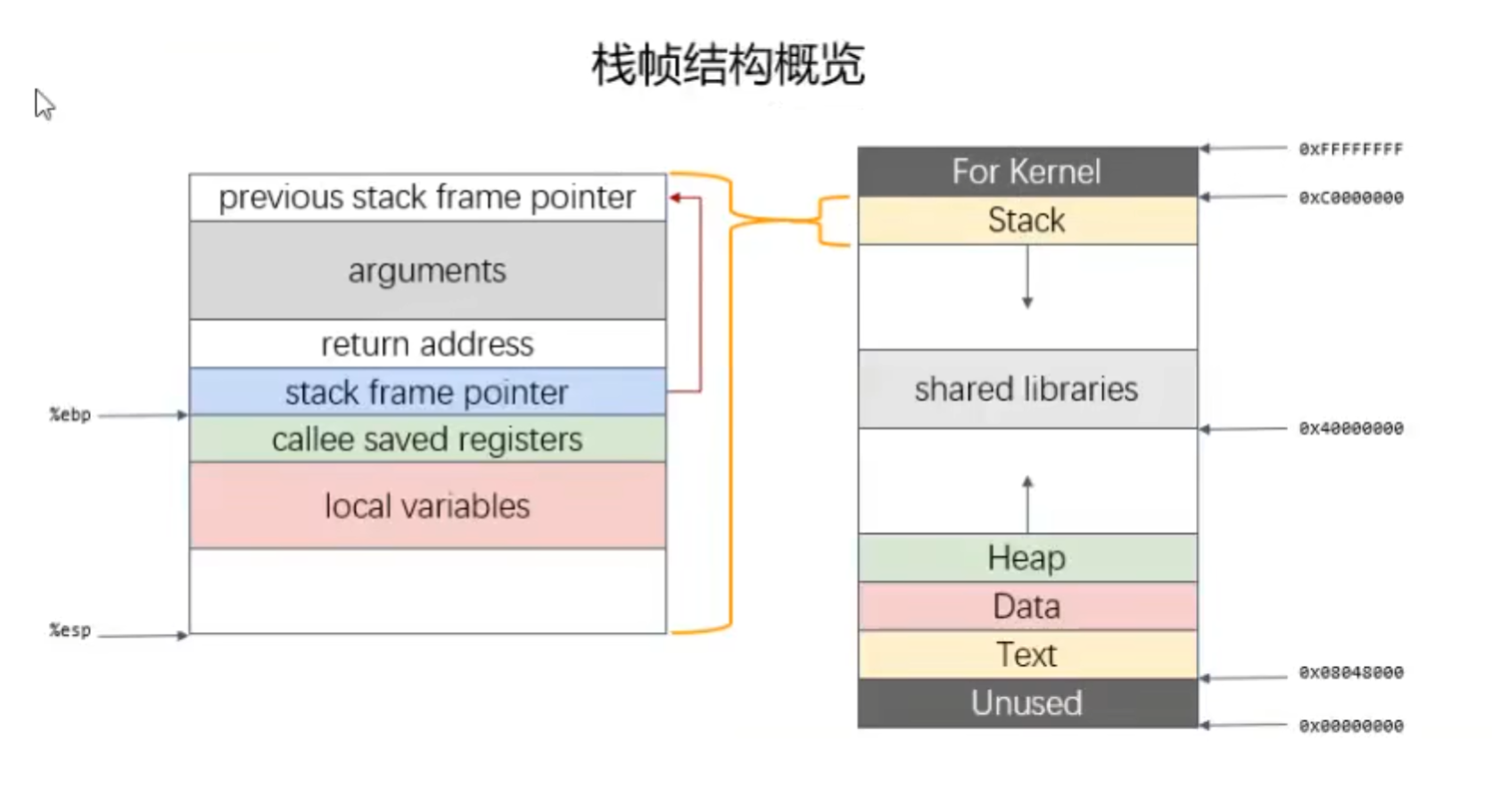
return address:返回地址
stack frame pointer:上一个栈帧的栈顶(ebp)的值。方便恢复父函数的栈顶指针
local variables:局部变量
arguments:子函数所用到的形参。 子函数保存的参数实际上在父函数栈帧的末尾。
能看出来吗,图中的例子是个循环结构
例子
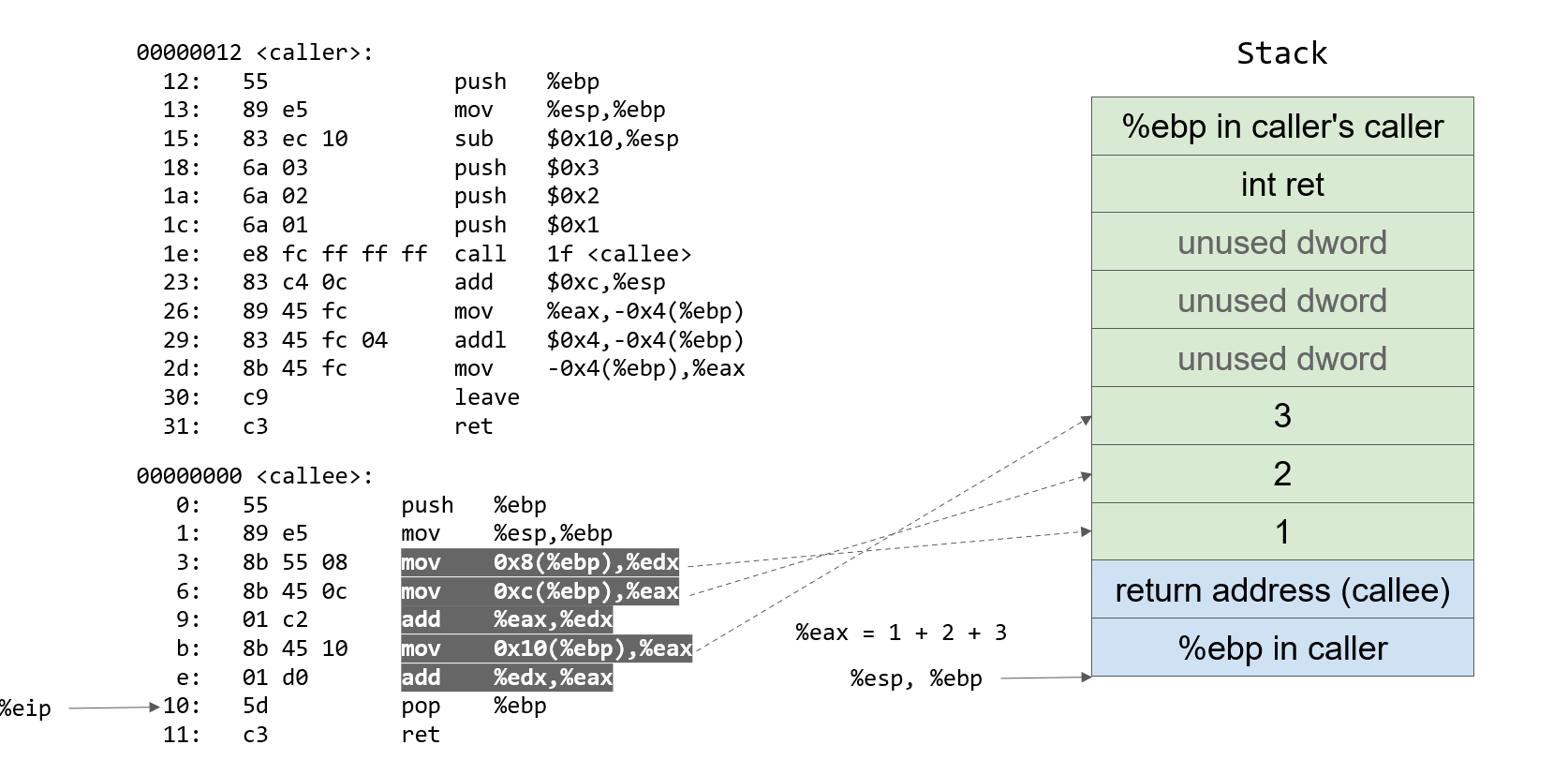
试试看能不能在没有讲解的情况下捋完整个过程。
不行看PPT去
main函数的栈帧是第一个栈帧,在此之前运行的函数是没有栈帧的
栈溢出攻击
要得到shell,就要控制程序的执行流
要控制程序的执行流,就要控制PC寄存器
要控制PC寄存器,就要控制能为PC寄存器赋值的数据
也就是要控制子函数返回父函数的 return address
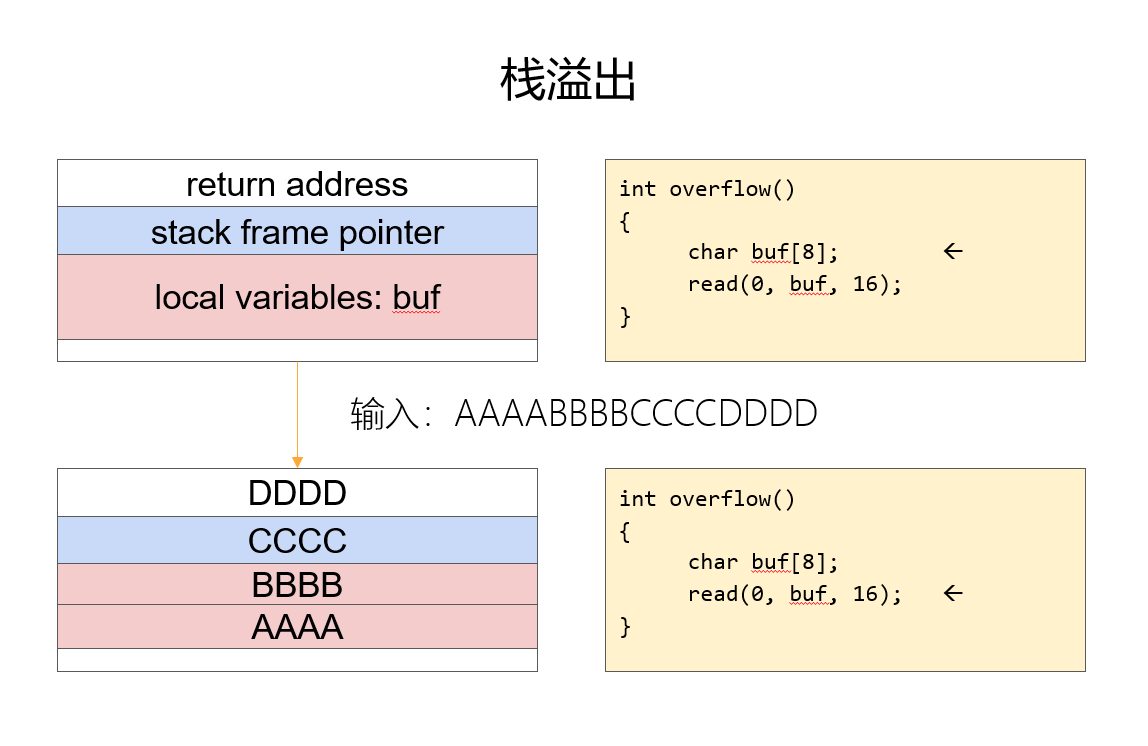
栈溢出是缓冲区溢出的一种。
缓冲区溢出的本质是向定长的缓冲区写入了超长的数据,造成超出的数据腹泻了合法内存区域
缓冲区溢出分为栈溢出、堆溢出和BSS溢出三种
例子
第六节:熟练使用工具
一切的开端
1 | from pwn import * |
执行文件
1 | io = process("./文件名") |
1 | io.recv() //读取全部输出 |

1 | io.sendline(p64"15") //自带换行。若是32位整数则是p32 |
IDA
g 跳转到指定地址
pwndbg
run 运行
r
b (break point) b main即运行完主函数
n 进行下一步
vmmap
注意gdb是用一种特殊的方式来进行的进程映像,所以gdb的栈地址(很大概率)不一定是可靠的地址。
但是gdb中看到的偏移一定是可靠的
相比IDA 中看到的偏移不一定可靠
机器码
shellcraft
shellcraft.sh() 输出汇编代码
print(shellcraft.sh() ) 这是我们要的shellcode
print(asm(shellcraft.sh())) 转化为机器码
以上是32位
如是64位
shellcraft.amd64.sh()
不过最好先加上 context.arch = "amd64"
刷题去吧,写题解
第七节:程序保护措施
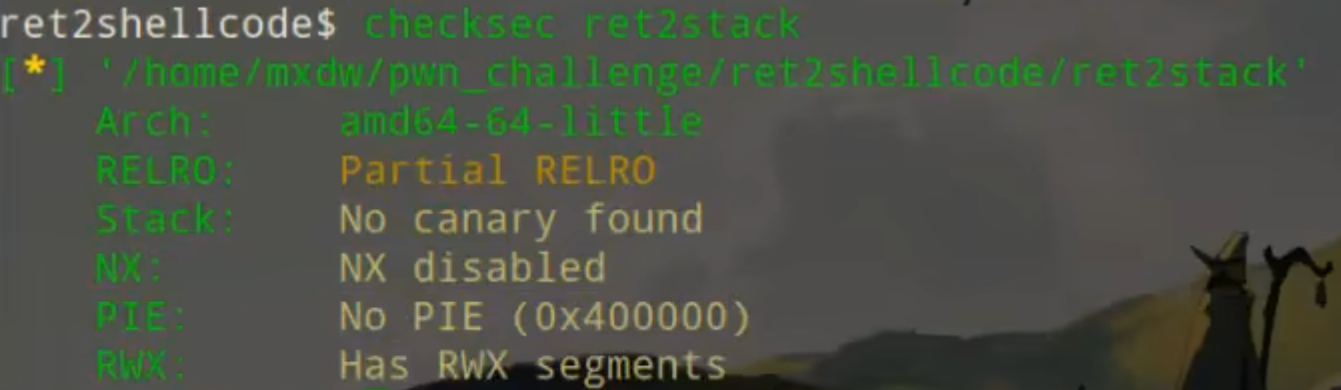
使用checksec查看
ASLR(Address Space Layout Randomization)
地址空间随机化。
系统的防护措施,程序装载时生效。操作系统默认打开
/proc/sys/kernel/randomize_va_space = 0:没有随机化。即关闭 ASLR
/proc/sys/kernel/randomize_va_space = 1:保留的随机化。共享库、栈、mmap() 以及 VDSO 将被随机化
/proc/sys/kernel/randomize_va_space = 2:完全的随机化。在randomize_va_space = 1的基础上,通过 brk() 分配的内存空间也将被随机化
攻击手段
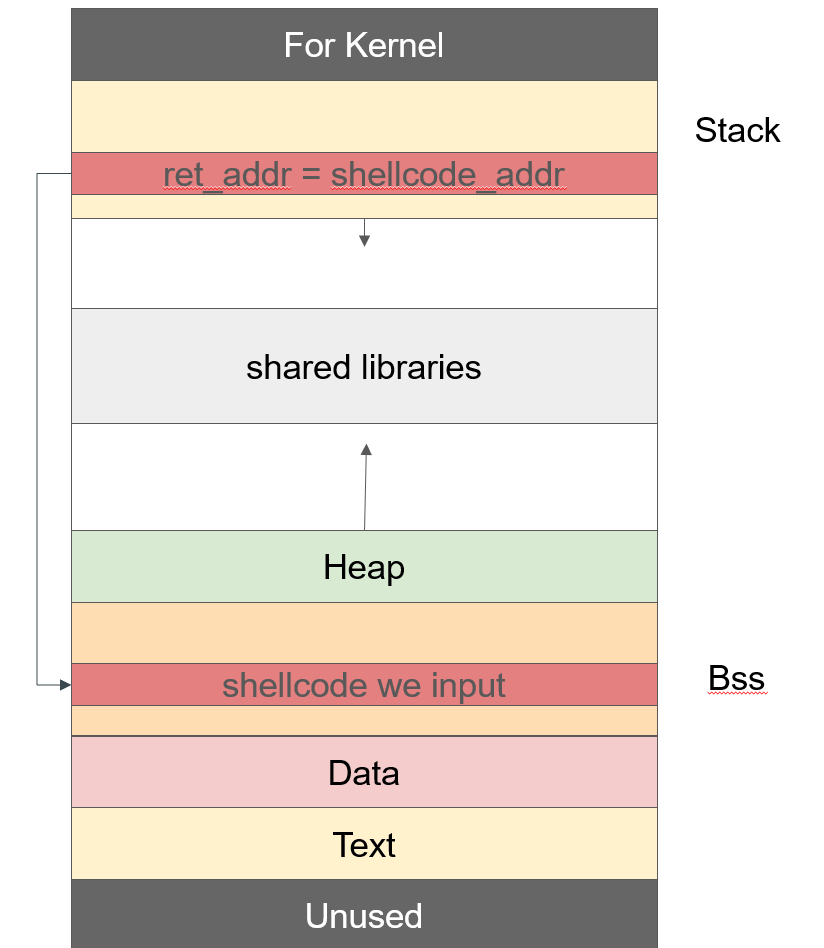
总的来说,这种保护措施使得栈地址和内核空间有一段不可知的偏移,导致在栈上写的shellcode无法知道准确地址。
如果缓冲区足够长,可以在shellcode下写入大量的nop指令(构造nop滑梯),一路向上执行直到运行shellcode
The NX bits (the No-eXecute bits)
栈缓冲区不可执行
只要不应该是代码的地方都不执行
所以一般思路将shellcode写入bss。 写入堆很少。但听说ctf很多
bss是用来存放全局变量的
Canary
在previous ebp前放了一个canary数组,内容为随机数
在栈帧销毁时(leave指令前),会检测Canary数组的值是否改变,如果改变程序会寄掉
PIE
编译器编译时打开的开关,与ASLR区分
随机化Data,Text和Bss
在脚本头上写下
1 |
|
生成程序后,checksec一下
第八节:返回导向编程
多次篡改IP成我们想要的地址的过程
和前面的栈溢出不同的是,以前的基础栈溢出可以一步到位(因为有后门函数或者可以注入shellcode)。而现在无了。
系统调用
- 是操作系统提供给用户的编程接口,这些接口可以被链接库封装成一个函数。
- 是提供访问操作系统所管理的底层硬件的接口
- 本质上是一些内核(Kernel)函数代码,以规范的方法驱动硬件
- x86通过int 0x80指令进行系统调用、amd64通过syscall指令进行系统调用
举例:
1 | void my_puts(){ |
这样一个代码,在操作系统层面是如何实现的:
1 | mov eax, xx |
动态链接库
什么是动态链接库?
使用ldd指令可以看到使用到的所有链接库

最下面的那东西,把我们所需要的所有动态链接库,文件,全部装载到shared library中。
我们要关注的是libc.so。这是一个软链接,不是一个具体的实现。
什么是软链接?
这好比我们的快捷方式。不管这个应用程序发生了什么样的改变,只要位置没变,这个快捷方式就可以打开这个应用程序。相比之,动态链接库也是在不断更新的,libc.so就充当了这个代名人。
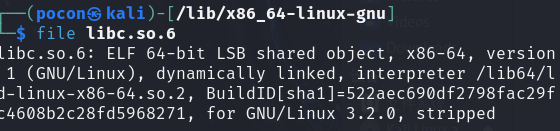
这里没绑定动态链接库啊。
如果绑定了就可以直接执行,相当于直接执行这个动态链接库
简而言之,动态链接库就是存放在lib目录的一些可执行文件而已,这些库里面已经包含了大量的已经写好的C语言代码。
而软链接就是动态链接库的一个快捷方式
同样看上面那个write的例子,在执行程序的时候,执行流为:
my_puts() ==> write() ==> sys_write()
从Text到shared library再到Kernel
各个函数都有对应的系统调用号,如write的系统调用号是4 。write函数是对sys_write这样一个系统调用的一个封装
ROP
一个重要的系统调用
execve
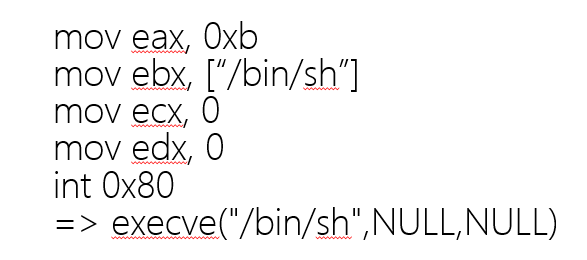
分析系统调用的过程:
首先赋值一个系统调用号(eax) (execev的系统调用号是11)
ebx,ecx,edx保存系统调用的参数
int(interrupt)中断,0x80代表的就是系统调用
所以我们首先知道这是一个系统调用,然后查看系统调用号看看这是哪个系统调用,最后传递参数执行
只需要这几条汇编代码就可以得到shell,但现实往往不会白白将这些代码连续得写到程序中。
不过,有这些程序片段也是可以的。
这就是ROP
让分离的代码连续执行,达到对应的效果
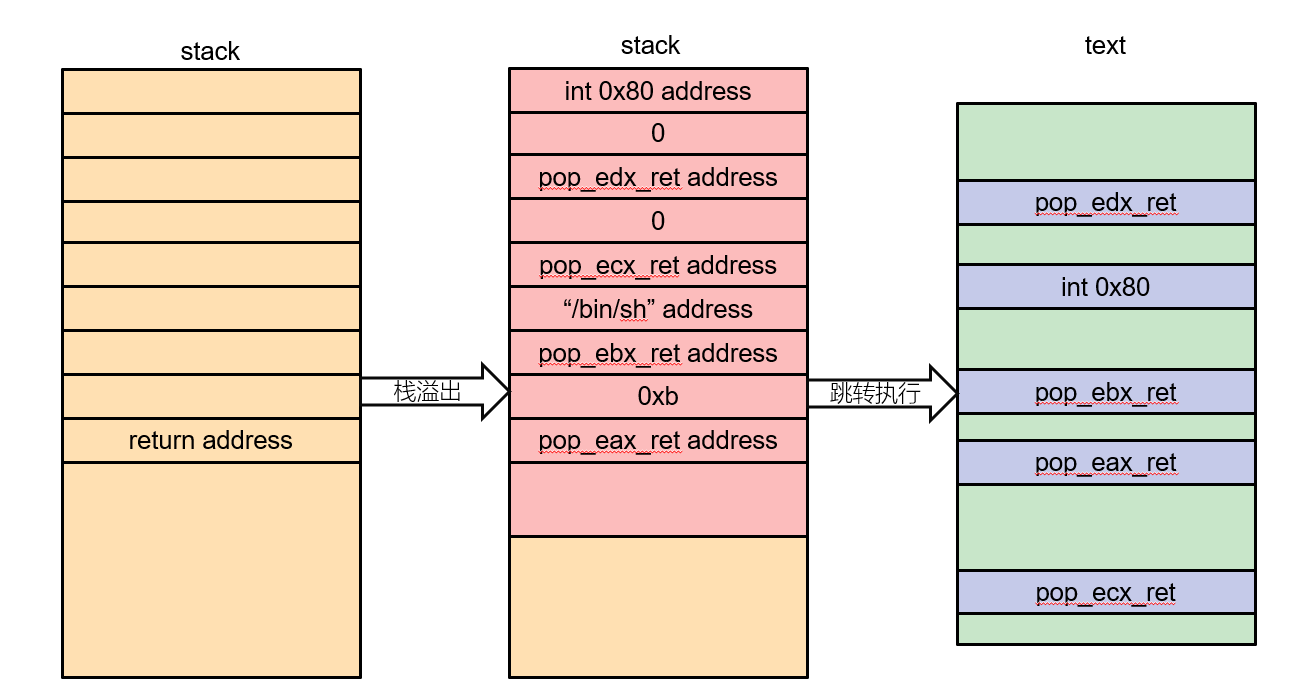
左边是程序执行的过程。原来的基础栈溢出只需要返回到后门函数或是某一个特定位置就可以了。
如今这个返回地址是一个链状的结构如今要执行四个不同片段(gadget)的代码,所以要跳转四次。
这个gadget就是这种,先pop(或mov,lea)一个数据给到寄存器,再ret的函数
不过pop比较好用。原因esp可以自动向上移,指向下一个IP地址。
(这个还真像链表,数据成员作为函数参数,指针成员指向下一个执行的地址)
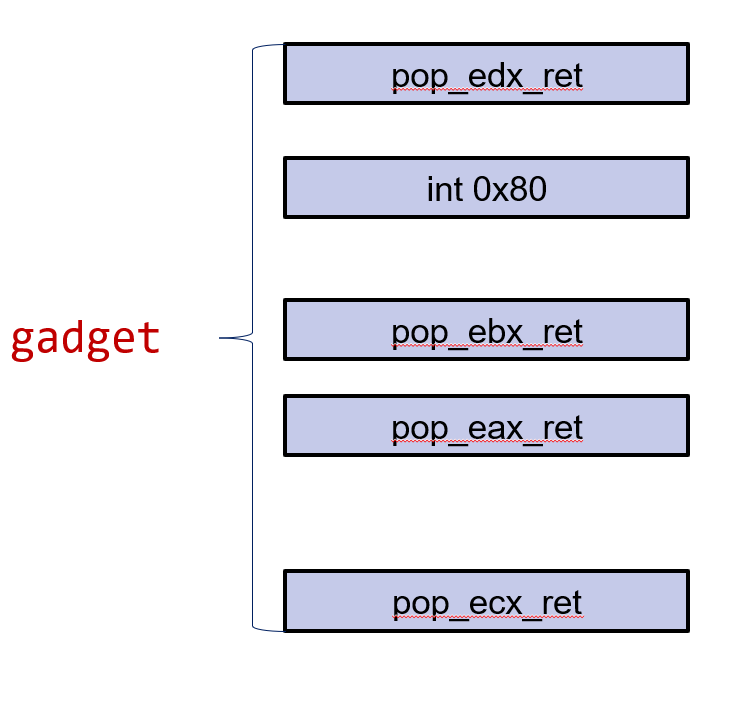
payload就像是一个个gadget搭起来的拼图
ROPgadget
使用这个工具可以找到需要的指令以及它的地址
即找到我们的gadget
ROPgadget --binary ret2syscall --only "pop|ret"
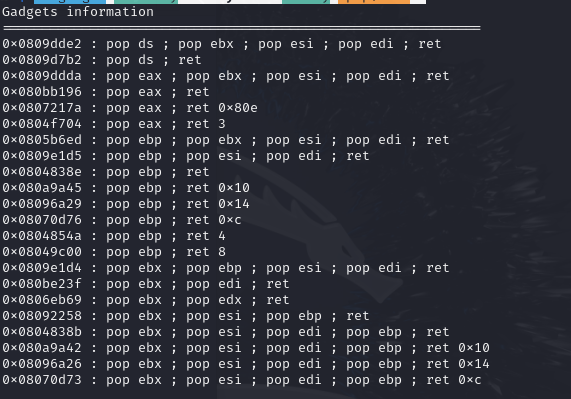
非常de好用
执行流程
gadget是mov,ret或是pop ,ret都可以。只要最后有个ret就可以无限执行下去。
因为ret可以改变程序的执行流(IP )。我们只需要将一系列返回地址或者数据溢出到栈中,就可以不断跳跃在各个gadget中。
- 栈溢出,让返回地址第一个gadget
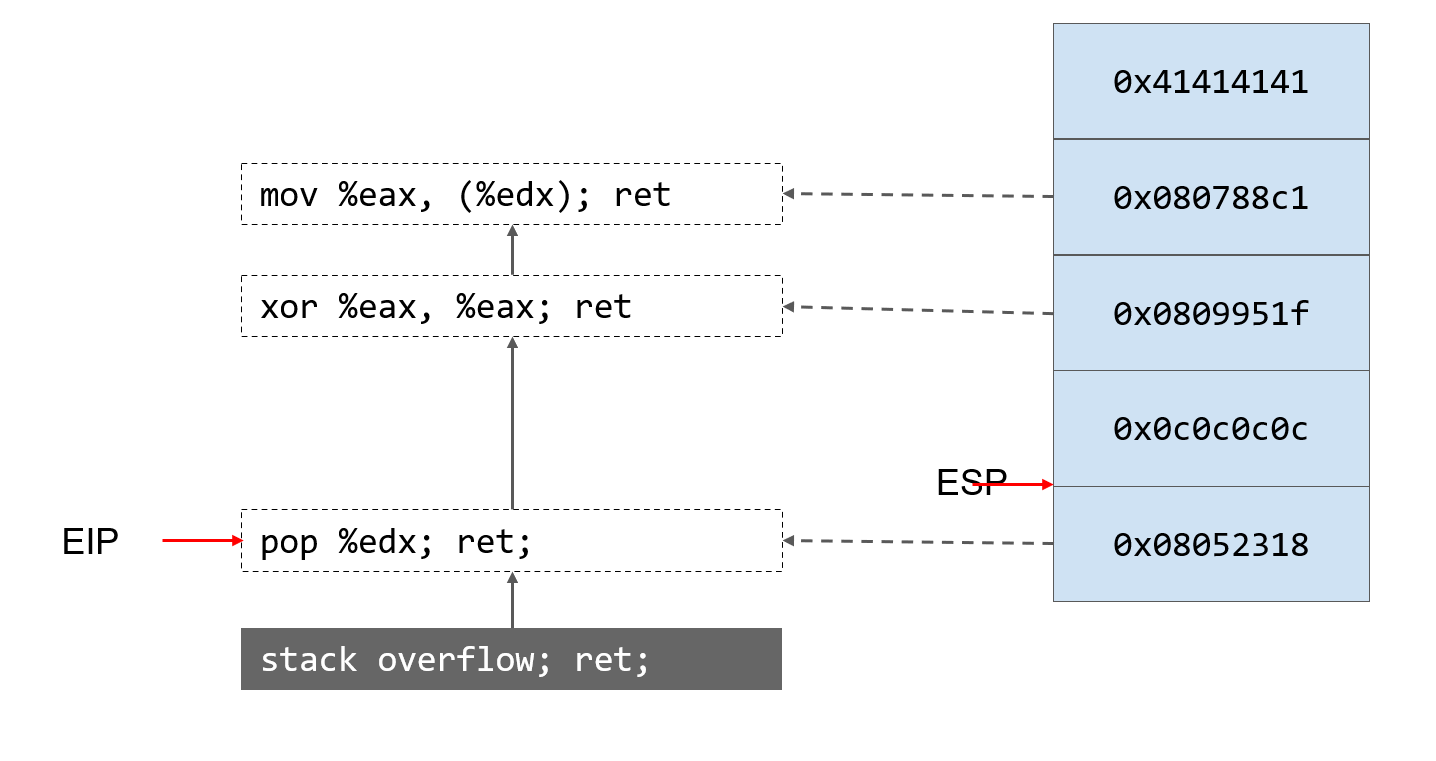
- 执行第一个gadget。将esp指向的元素赋值给edx,esp自增指向新的返回地址
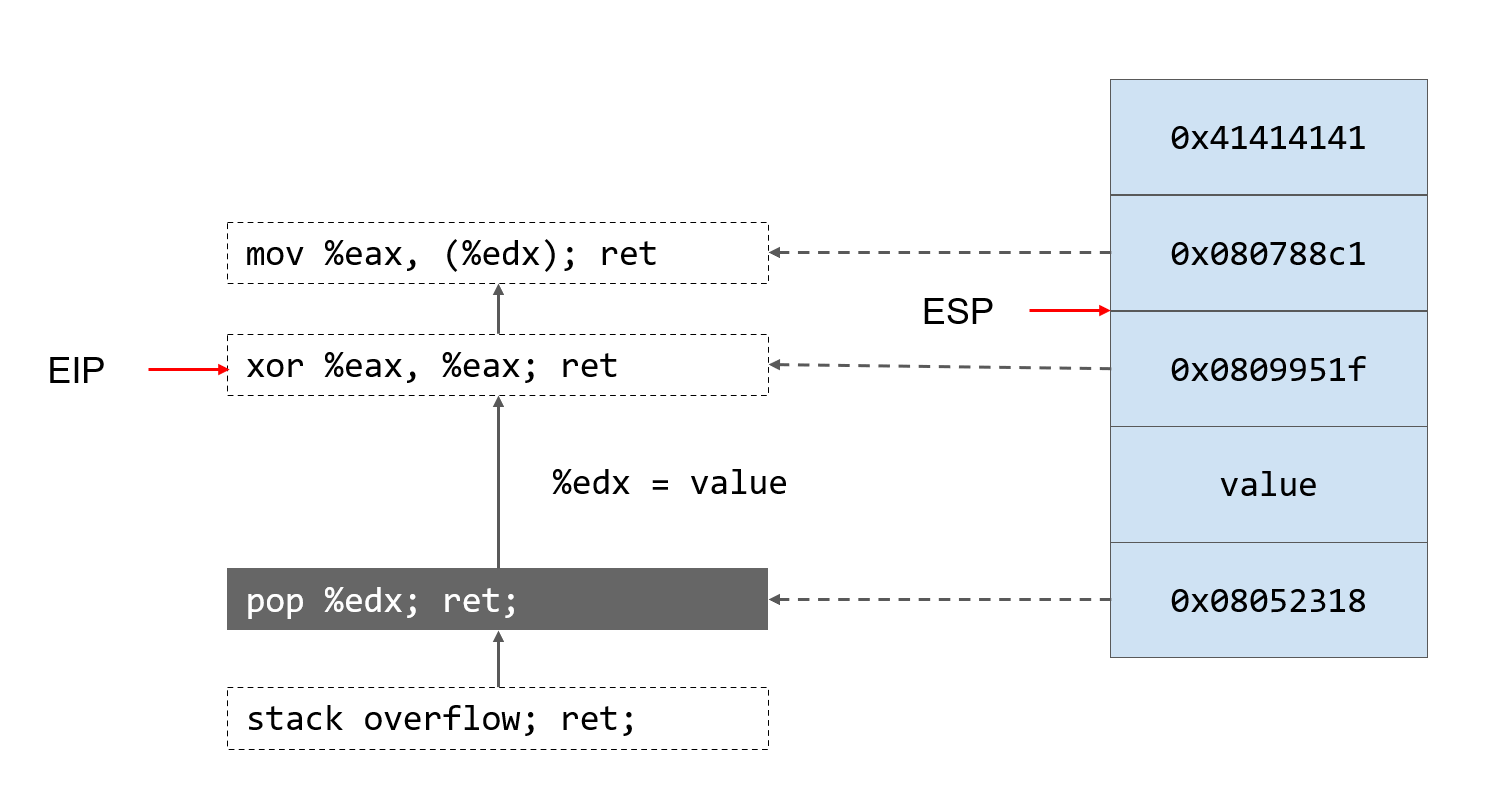
- 执行第二个gadget。将eax清空,返回esp所指向的地址
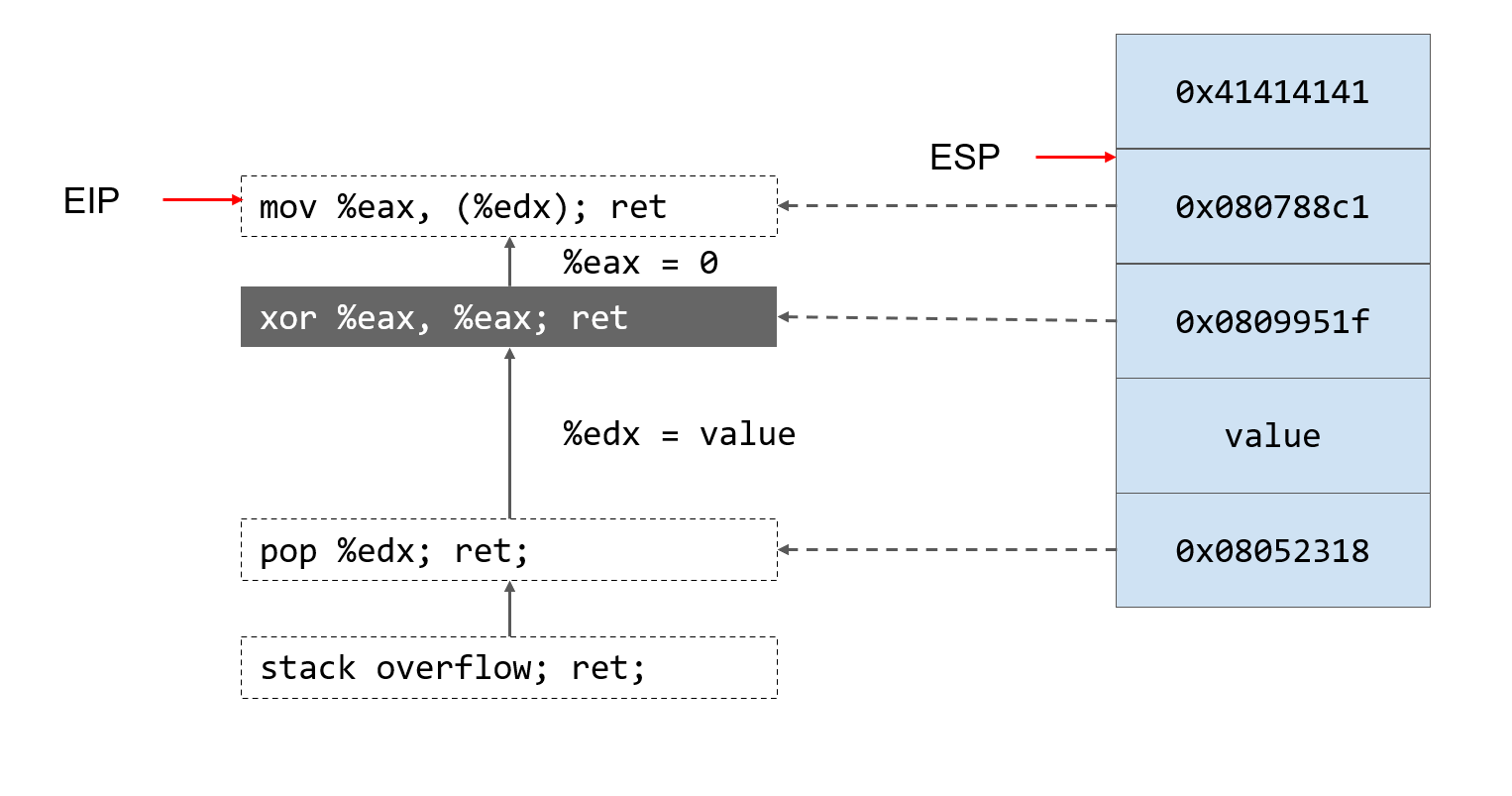
最终执行过程就像这样
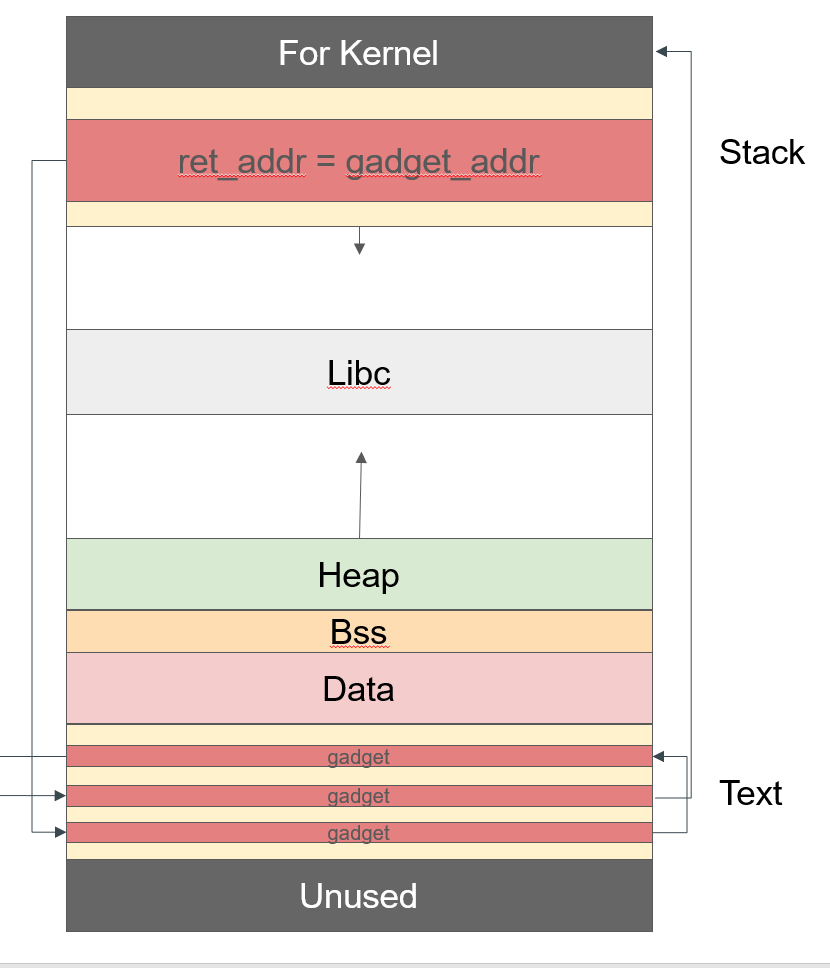
在栈中溢出一系列的返回地址,链式执行一系列的gadget。最后执行int 0x80指令,成功执行系统调用。这样就达到了攻击的目的。
图中最后从Text段到Kernel中执行的系统调用。
动态链接 vs 静态链接
动态链接:将用到的库函数标记一下。动态链接是在装载(从可执行文件到进程映像)的时候才可见。程序装载进入内存时加载库代码解析外部引用
静态链接:本身将库函数全部写入elf文件本身。静态链接在链接(从目标文件到可执行文件)时可见。链接器在编译链接时将库代码加入可执行文件中
所以两种文件大小差距很大。差的就是库的内容
可以在ida中看看两种不同方式中的函数数量

像这种粉色背景的函数,都是在程序中没有具体实现,只是一个符号而已。这个符号是用来解析函数在动态链接库中的位置。往往一个动态链接还要调用更底层的一些动态链接。
所以ret2syscall这题要用静态链接,用来提供足够的gadget
动态链接的相关结构
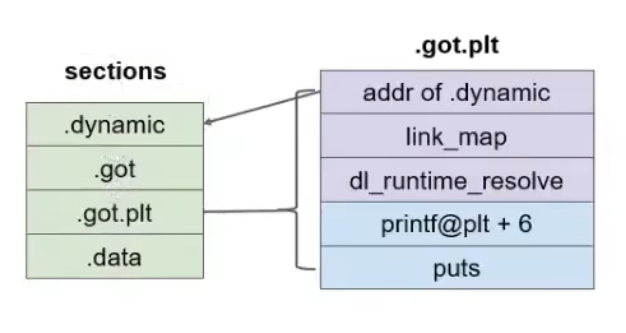
dynamic section:提供动态链接相关信息。包括整个动态链接的所有内容,包括其他的表,位置,如何组织
link_map:保存进程载入的动态链接库的链表。除了基本的动态链接库,可能载入了其他的动态链接库。这些所有的动态链接库所形成的可执行文件就会在lnik_map中形成一个链表
dl_runtime_resolve:是一个函数,解析第一次在动态链接的程序中执行的函数的真实地址。由plt调用,向got写入真正地址的内容
.got section:全局偏移量表,保存了全局的变量
.got.plt section:保存了函数的地址
动态链接过程
例子:调用libc中的foo函数
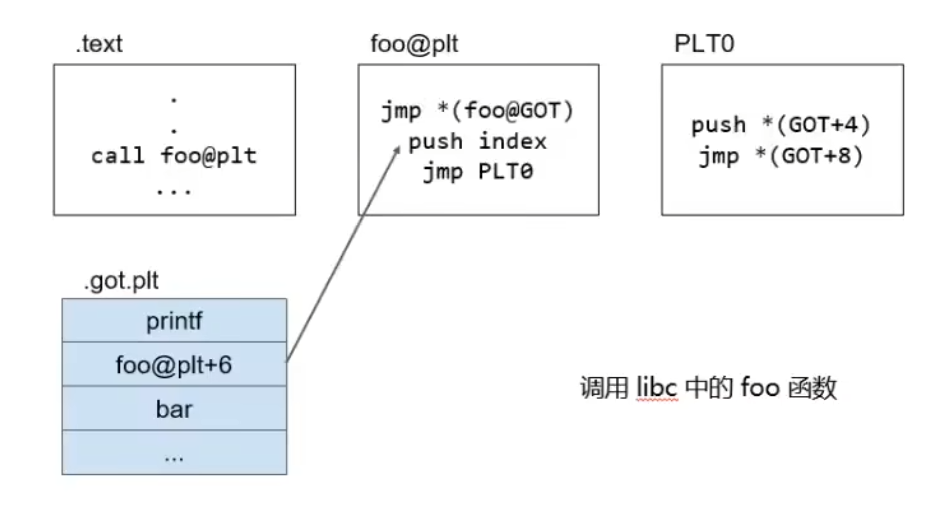
text是代码节
foo是我们写的自定义函数
plt是程序中代码段解析函数真实地址的一个节
(假设libc中有一个foo函数)
1 |
|
在汇编中调用一个用户函数会进行一个call指令。所以就会有一个call foo
因为foo是一个动态链接库中的代码。所以call foo不能够直接跳转到它自己的代码段里的库里。实际上在libc.so里的一段。但也不能直接跳到libc里,因为不知道具体位置
code段里还有一个plt节(所以plt本质上也是一些代码)。每一个动态链接库中调用的函数,都会在plt节中创建一个表项。
第一次调用foo时如下
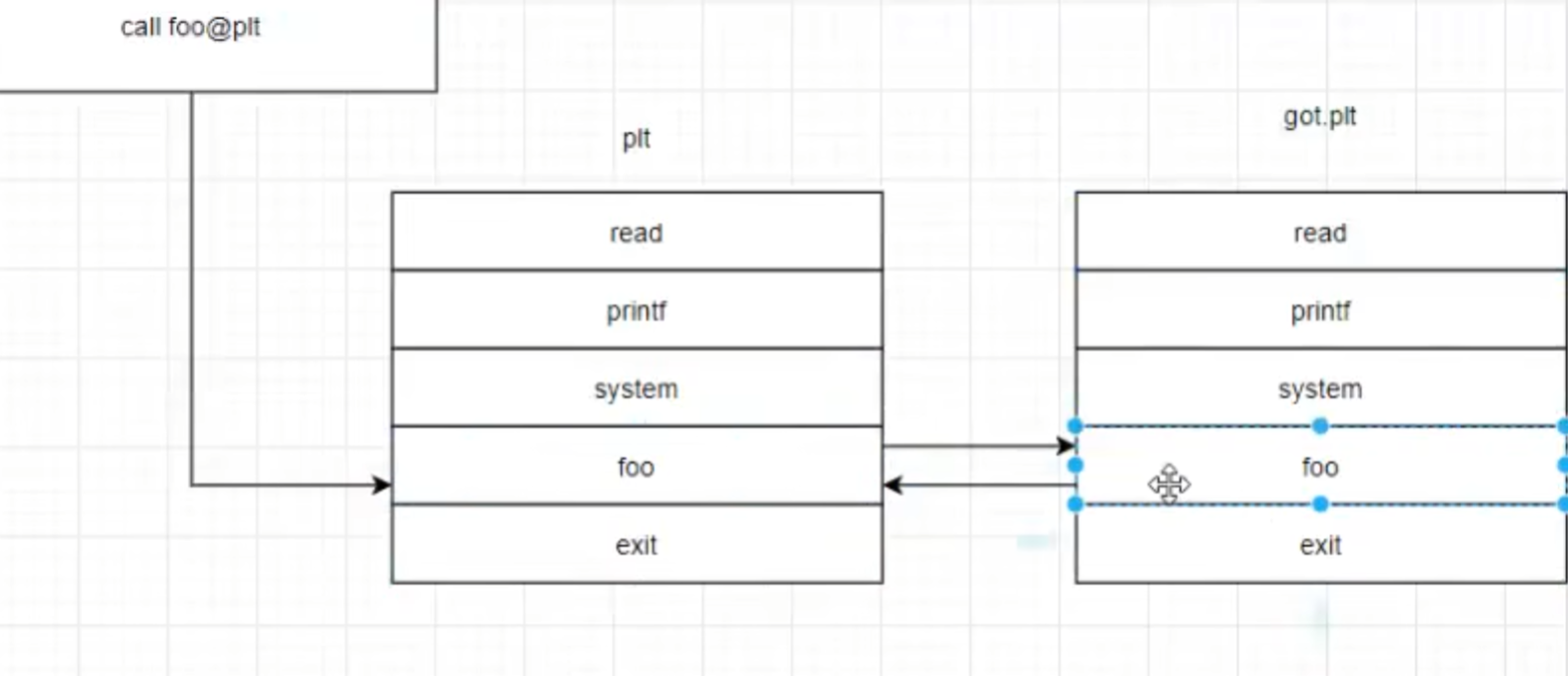
plt中存储foo函数的表项位置,通过此再从got表取得foo的真实地址。但是由于是第一次调用foo函数,got表并没有经过特殊函数解析,所以并没有填写真实地址。此时填写表项位置,从got表跳回了plt位置。这个时候plt表就知道了got表没有真实地址,并开始寻找foo函数的真实地址,填入got表中。
再回到最上面的那张图。
jmp到got表发现没东西,于是回到plt表。执行下方指令
首先push index。这个index就是在plt表中调用函数对应的索引。如上图为例,foo函数的index就是3。这里的意思就是说我要解析的是plt表中的第3个函数。
接着push *(GOT + 4)。表示要去哪个动态链接库去找需要的内容。接着jmp (GOT + 8 )进入dl_resolve函数。如下图
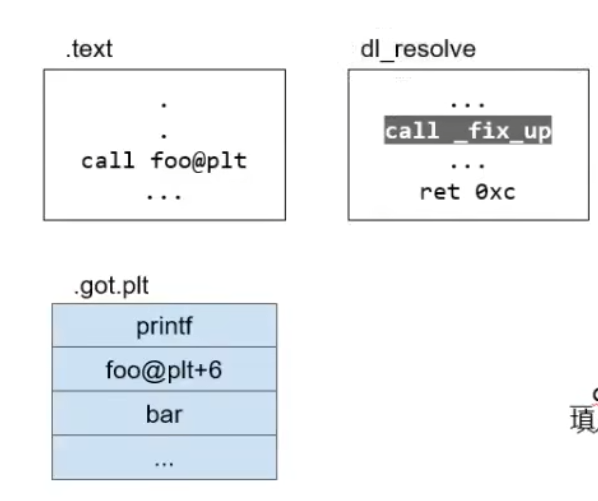
此时dl_runtime_resolve函数解析foo的真正地址填入.got.plt中
解析过程就不说了
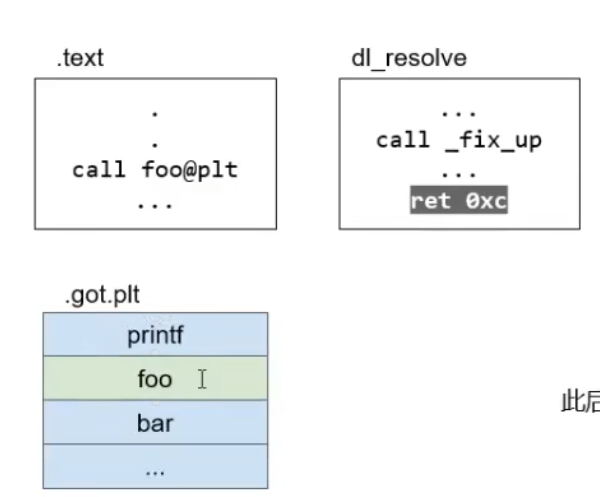
解析完毕后,就将foo函数真实地址的值填入got表中
如果变为第二次调用
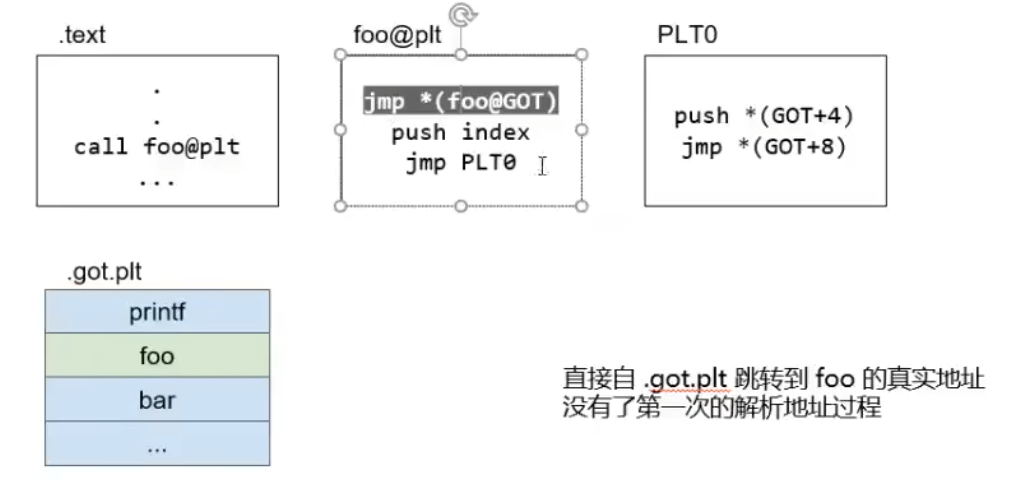
整个过程如下:
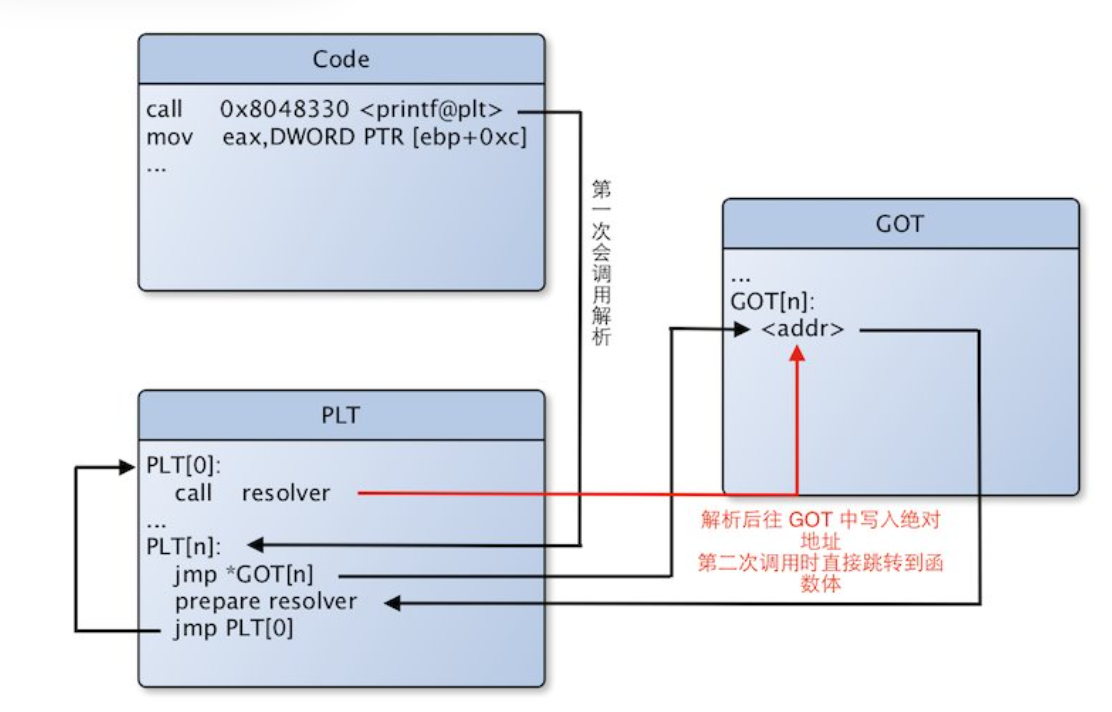
现新写一个程序,并使用动态链接
1 |
|
我们在ida中看看plt表

索引0这块就是put的表项、索引1这块就是printf的表项、索引2这块就是exit的表项
每个表项的长度都是16字节
在pwndbg中输入plt即可查看plt表,或者使用二进制查看plt内容 如 x/20 <plt的地址>

plt存在text节或init节这些代码中,作为数据存在的got节和got.plt节,在data段中
在ida中看看got表
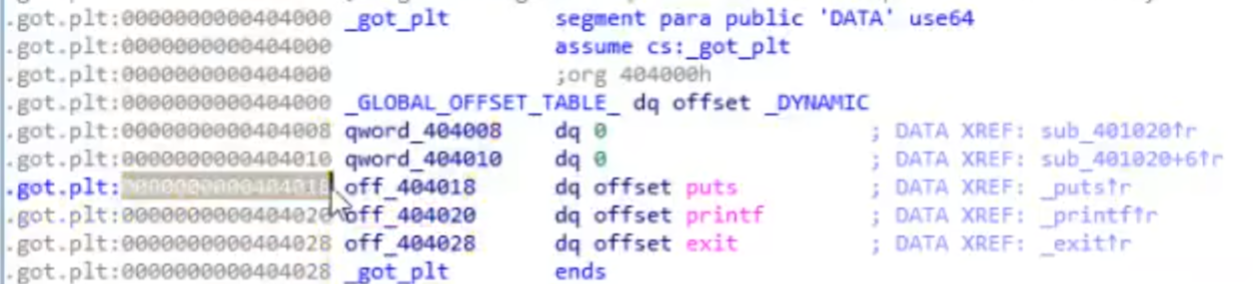
这个got表实际上是一个数组,元素长度位8字节(64位程序地址长度)。每一个表项就是地址而已。
直接输入plt可以看到三个表项
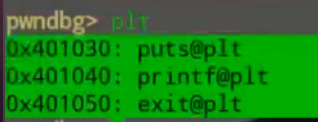
一个表项是十六个字节
再输入got
这里是程序刚刚开始运行的时候

告诉我们got表中存了三个函数,每个函数8字节。每个地址都是0x000000000040……,并且告诉了我们再plt表中对应的索引
这个地址对应代码段(看颜色也能看出来),还是plt中的位置,也就是说这个时候got并没有存储这些函数的真实地址
接着步过调用puts函数后

这个时候可以看到,got表中已经填入了puts函数的真实地址
我们得到这个真实地址,并使用disass指令反汇编,就可以得到puts函数真正的代码
如果我们disass没有调用的函数,得到的就是plt中的代码:

pwnttool中elf模块
elf = ELF(“./文件名”)
hex(elf.got[“puts”]):得到puts函数在got表中的表项的地址
6y